Matthew Bennett

I am a data scientist working on time series forecasting (using R and Python 3) at the London Ambulance Service NHS Trust. I earned my PhD in cognitive neuroscience at the University of Glasgow working with fmri data and neural networks. I favour linux machines, and working in the terminal with Vim as my editor of choice.
Projection and regression
Often there is no solution to $Ax = b$. Usually in practical applications we have a large set of data points $b$ that we want to fit with a model - the columns of $A$ - with only a few parameters - stored in $x$ - much fewer parameters than we have data points. Our model matrix $A$ is tall and thin, and so has no inverse! $x = A^{-1}b$ is not an option to find the parameters in $x$.
The data points contain some measurement error or 'noise' and we don't want our model to fit this noise. We want our model to capture informative trends, that will generalise to new data with different noise. Therefore we have to accept some discrepancy between our fitted model and the data. We want to minimise this 'model error' when we fit.
Since we can't find an $x$ that satisfies $Ax = b$, we look for a 'best $x$' that comes close: \(\hat x\). The $b$ doesn't fall into the column space of $A$ (henceforth $C(A)$) whereas \(A\hat x\) does, so we project $b$ to the closest point in $C(A)$. This implies that the 'error' is the shortest vector $e$ needed to 'bridge the gap' from $b$ to $C(A)$:
The vector $e$ is perpendicular to $C(A)$ and so is in the nullspace of $A^T$ (henceforth $N(A^T)$):
The equation can be expanded to:
Rearranging::
Therefore, our best estimate of the parameters of the model is:
And the vector that will be in the $C(A)$ (that is the 'predicted values' of our model) is:
Thus we arrive at a matrix to 'project' some vector into $C(A)$:
Code implementation
We define two methods, the first gives both the general projection matrix $P$ and the matrix 'for_x' that multiplies $b$ by the $P$ to give \(\hat x\). The second projects the column(s) of a vector/matrix $B$ and projects them onto $A$ to yield \(\hat x\):
def projection(self):
# P = A((A'A)^-1)A'
AtA_inv = (self.tr().multiply(self)).inverse()
for_x = AtA_inv.multiply(self.tr())
Projection = self.multiply(for_x)
return Projection, for_x
def project_onto_A(self, A):
_, for_x = A.projection()
projected = for_x.multiply(self)
return projectedNext we define a method to give the parameters for an nth degree polynomial curve through a set of data points in $b$. Here we use the vandermonde matrix $V$, we defined earlier and project onto it to give \(\hat b\):
def polyfit(self, order=1):
V = vandermonde(self.size(0), order=order)
# fit model to b
return self.project_onto_A(V)Then we define a method to fit a straight line. This is the default of the polyfit method, but fitting a straight line is so common that it's nice to have a more descriptive method to call:
def linfit(self):
return self.polyfit()Demo
Below, we define a helper function and try this method out on a small sample. We fit a straight line, a 2nd degree polynomial, and a 7th degree polynomial:
import linalg as la
# regression
def quick_plot(b, orders=[1]):
fig = plt.figure()
Xs = [i/10 for i in range(len(b.data[0])*10)]
for idx, order in enumerate(orders):
fit = b.tr().polyfit(order=order)
Ys = []
for x in Xs:
y = 0
for exponent in range(order+1):
y += fit.data[exponent][0]*x**exponent
Ys.append(y)
ax = plt.subplot(1,len(orders),idx+1)
d = ax.plot(Xs[0::10], b.data[0], '.k')
f = ax.plot(Xs, Ys, '-r')
ax.set_ylim([0, max(b.data[0])+1])
return fig
import matplotlib.pyplot as plt
b = la.Mat([[2,1,3,5,1,4,6,3,4,7,7,8,7,6,5,7,8,7,9,7,6,6,9]])
fig = quick_plot(b, orders=[1, 2, 7])
plt.show()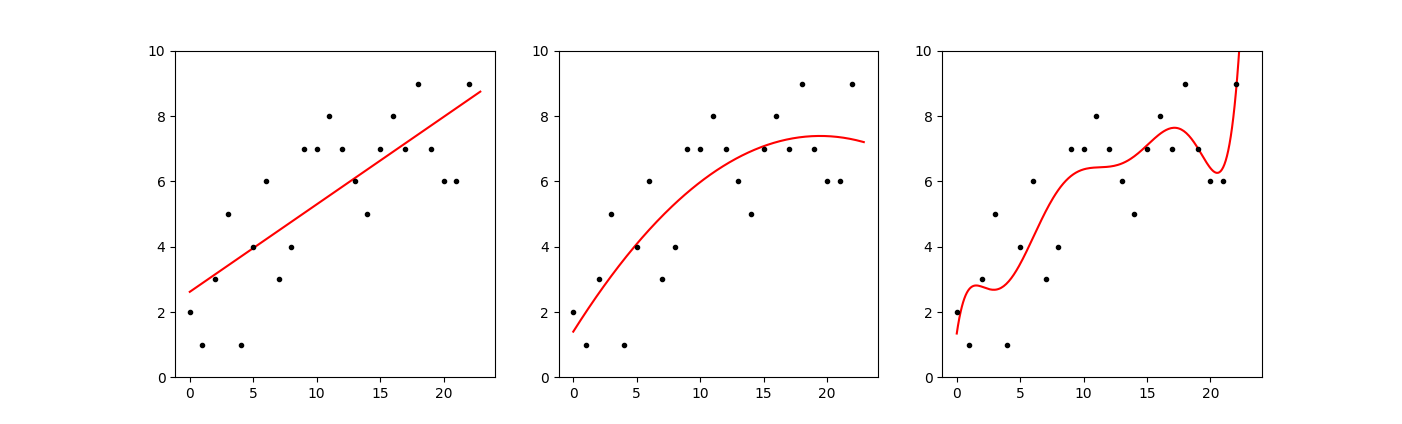
back to project main page
back to home