Matthew Bennett

I am a data scientist working on time series forecasting (using R and Python 3) at the London Ambulance Service NHS Trust. I earned my PhD in cognitive neuroscience at the University of Glasgow working with fmri data and neural networks. I favour linux machines, and working in the terminal with Vim as my editor of choice.
Creating a searchable database of UFC contests using web-scraping in Python 3
The full code I’ve written so far can be found here.
The Goal
I'm a fan of the Ultimate Fighting Championship (UFC), and often I want to watch an old fight of a particular fighter but I don't remember all their previous opponents or which UFC events they performed in.
I decided to create a simple database containing a row for each fight in each UFC event, the weight category and fighter names. Then I can simply pipe the file contents into fzf and I have an interactive searcher which quickly shows me all the UFC cards on which that fighter had fought and who their opponent was.
With the following alias in my .bashrc file:
alias ufc='cat ~/ufc/ufc_database.txt | fzf | sort'I can easily whittle down the results to a specific fighter:
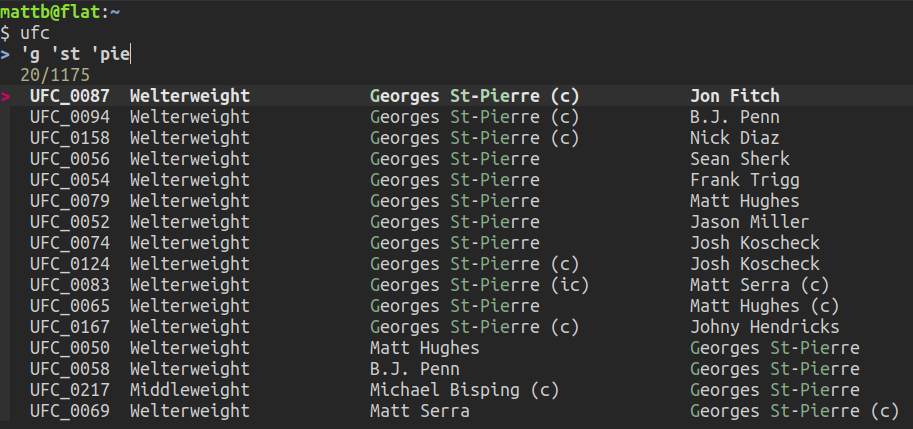
The selected results are sorted and sent to STDOUT:
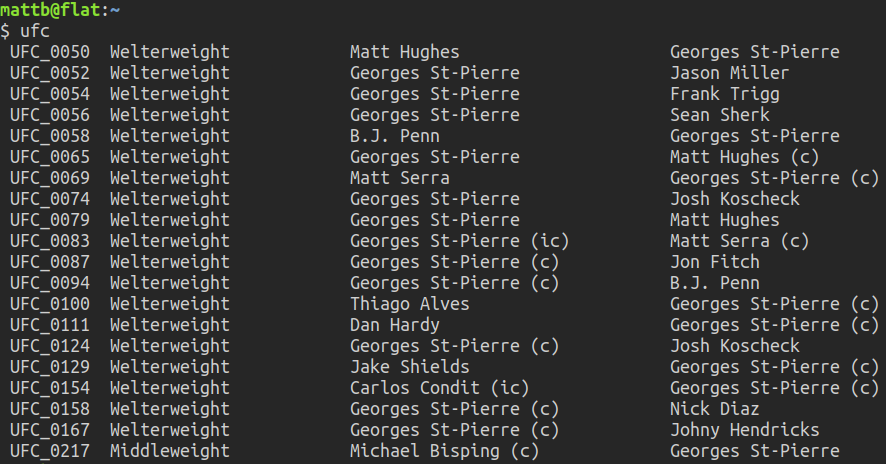
The Plan
Wikipedia has a page listing all UFC events and features a table containing links to a page about each event. On these individual event pages there is a table containing information I want. So what I want is to have a python script that can go to the list of events page, follow up each link to individual event pages, and pull the correct table.
We'll get the link urls using BeautifulSoup. Handily, there is a dedicated module just for accessing the html for of any Wikipedia page. Once we have the html, we can use the pandas module to read the table of interest into a dataframe object. Then it's a matter of cleaning the data and entering it into the database. The goal is the following txt file (containing 1175 fights):
Event Weight Fighter1 Fighter2
UFC_0020 Heavyweight Bas Rutten Kevin Randleman
UFC_0020 Heavyweight Pedro Rizzo Tra Telligman
UFC_0020 Heavyweight Pete Williams Travis Fulton
. . . .
. . . .
. . . .The Code Implementation
After importing the modules we initialise a table:
from bs4 import BeautifulSoup as bs
import requests
import re
import pandas as pd
import wikipedia as wp
from prettytable import PrettyTable
import random
# initialise a table object with column names
t = PrettyTable(['Event', 'Weight', 'Fighter1', 'Fighter2'])
t.align='l'
t.border=False# grab all the links on the List_of_UFC_events wiki page
res = requests.get("https://en.wikipedia.org/wiki/List_of_UFC_events")
soup = bs(res.text, "html.parser")# latest event already in the database will not be pulled in again
latest = 255
# future events will not be pulled in either
future = 259
# avoid visiting the same page more that once
tried = []
with open("~/videos/ufc/ufc_database.txt", "a") as f:
for link in soup.find_all("a"):
try:
url = link.get("href", "")
# if the link looks like a ufc event that we've not tried yet
if bool(re.search('UFC_\d+$', url)) and (url not in tried):
tried.append(url)
# get the even number
event = int(re.findall('\d+$', url)[0])
if event > latest and event < future:
print(url)
# read the page
html = wp.page(url[6:], auto_suggest=False).html().encode("UTF-8")
# pull 3rd table
df = pd.read_html(html)[2]Next we put a zero padded UFC event number - this will allow us to sort the database chronologically when we're done. After re-indexing the dataframe we extract the data we want and label the columns.
Then we extract the section of the table that lists fights that appeared on the main card (skipping the preliminary fights) and convert data to comma separated string:
# put the zero padded ufc number as the Event column
df.insert(0, "Event", ('UFC_' + url[10:].zfill(4)))
# get rid of columns I don't want (brittle approach...)
df = df.drop(df.columns[[3,5,6,7,8]], axis=1)
# change df from a multiindex to single indexed object
df.columns = df.columns.get_level_values(0)
# rename the colums sensibly
df.columns = ['Event', 'Weight', 'Fighter1', 'Fighter2']
# find where the prelims start
index = df[df['Weight'].str.contains('Preliminary')].index[0].item()
# select only the main card
df = df[:index]
# strip the indices and column names and convert to csv string
data = df.to_csv(index=False, header=False)
# each line is a list item contatining a csv string
data = data.splitlines()# shuffle order of fighters (the winner is always listed first)
for line in data:
entries = line.split(',')
copy = entries[2:]
random.shuffle(copy)
entries[2:] = copy
# add each csv to a column which is nicely aligned
t.add_row(entries) # just move on from any errors
except:
print('error')
pass
# if we're just adding to an existing database, the header already exists
if latest > 0:
t.header = False
# sort into chronological order and save
f.write(str(t.get_string(sortby=('Event'))))
f.write('\n')The full code I’ve written so far can be found here